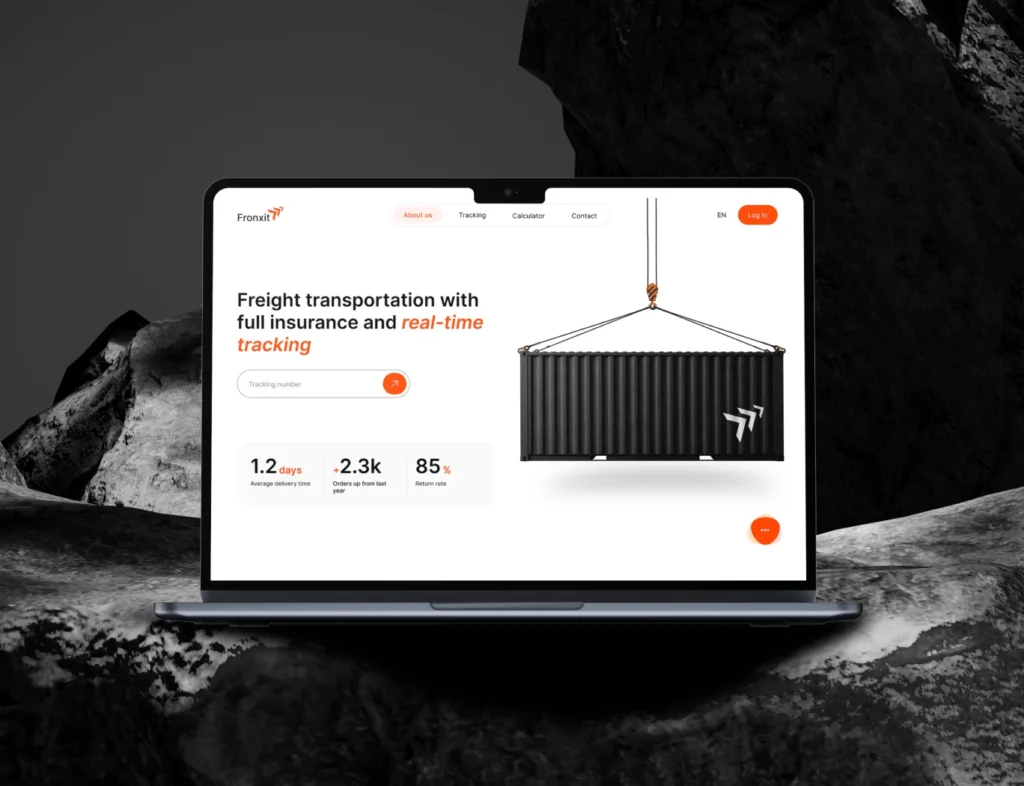
Developing a Flexible IT Education Platform for Global Learners
Our client, under NDA as a subcontract, sought to create a mobile application designed to offer IT courses and tutorials. The goal was to introduce a more flexible alternative to well-known education platforms already existing in the US market. The app needed to provide a seamless and personalized educational experience, allowing users to easily find, manage, and track their learning progress. The project required a robust technology stack, a user-centric design, and features that catered to both learners and content creators.
 OutSoft
OutSoft



















 AWS
AWS 



 Jenkins
Jenkins 






 Сloudfront
Сloudfront  Сloudflare
Сloudflare 
 Gitlab
Gitlab 
 Digital
Digital  MSK
MSK  Redis
Redis  Open Search
Open Search 

 Terraform
Terraform  Ansible
Ansible 
 Kuberneres
Kuberneres 
 Prometheus
Prometheus  Integration with Slack
Integration with Slack 
 Java
Java  C
C  Websockets
Websockets  Dynamodb
Dynamodb 





















